
Alphabet Inc., Google’s parent company, was formed following a restructuring of their entire multinational group on October 2, 2015. That enterprise comprises Google and several subsidiaries in several other industries, including the AI subsidiary DeepMind.
Today, most of the company’s products use some form of AI. The company owns several AI-focused subsidiaries in the transportation, logistics, infrastructure, cybersecurity, and healthcare industries.
Alphabet is traded on the NASDAQ (symbol: GOOGL) and has a market capitalization of approximately $1.4 trillion. In its 2021 annual report, Alphabet reported revenues of roughly $257 billion. In the same report, Alphabet cites its number of employees as 156,500.
Two use cases in particular best represent how AI initiatives support Alphabet’s current business strategy:
- Improving search for online shopping: Google uses machine learning to to help shoppers find their items faster.
- Defending against email malware –
Use Case #1: Improving Search in Online Shopping
Google initially faced difficulties when trying to scale its product classifier system. When the company added more items to its system to be placed into the correct product category, Google’s AI team found that the existing algorithm would not adapt to include the new items. For example, a handbag – a “fashion accessory” item – would not be recognized as such by the algorithm. When this happened, a Google worker had to relabel the data manually.
Google was then forced to manually alter the input data of hundreds of different classifier models, each with its own training dataset, every time the algorithm didn’t accept a new product. This mass manual effort was considered to be a waste of time and resources at the time. Google purportedly spent months and “considerable resources” manually labeling and relabeling thousands of mislabeled and unrecognized data points.
The company eventually sought a comprehensive solution that could label data faster and adapt and develop new classifiers.

Example of product misclassification and manual relabeling (red font).
Source: Snorkel
Snorkel claims that it replaced Google’s manual, one-by-one label labeling process with one that speeds up the development of two content classifier types – product and topic – using machine learning. The idea was to develop a system capable of maintaining the accuracy of manual hand-labeling but in a portion of the time.
To accomplish this, Google purportedly applied weak supervision machine learning. Weak supervision is simply the use of “noisier” data to create more robust data sets and reduce training time.
First, a Google developer spent some time writing labeling functions used internally at Google. Examples of labeling functions for the product classifier include:
- Keyword-based: Keywords designated accessories or products in a product category determined to be “of interest” or “not of interest” to the particular user.
- Knowledge graph-based: Querying Google’s knowledge graph for translations of keywords that could increase the number of relevant searches for each product category.
- Model-based: Use of a semantic-based model to identify content unrelated to products within the category of interest.
Regarding tangible business results, Snorkel claims that its labeling system was able to perform the amount of data labeling in 30 minutes that previously took Google six months. Snorkel cites 6.5 million data points labeled for a product classification model in 30 minutes. The company also reported a 52% “performance improvement,” although Snorkel does not explain this metric criterion.
Use Case #2: Defending Against Email Malware
As of 2019, Google claimed that Gmail had 1.5 billion users worldwide. These users open hundreds of millions of emails on the platform daily, many of which contain attachments and a small minority of attachments therein contain malware.
Elie Bursztein, who leads Google’s Security and Anti-Abuse Research team, says, “Every day, Gmail defenses analyze billions of attachments to prevent malicious documents from reaching the inboxes of its users, whether they are end-users or corporate ones.” Google states that every type of organization is susceptible to being targeted by malicious documents.
In his 2020 RSA Conference presentation, Bursztein claims that Gmail scans over 300 billion attachments for malware weekly. The company says it accomplishes this scale by implementing deep learning through pattern recognition by AI-enhanced document scanning.
The AI appears to work in three separate stages. First, the model determines if the attachment’s file type is acceptable. Google lists all of the different file types that are not allowed as attachments on its support website.
Second, the software runs the attachment through different document “scanners,” which use a tool called feature extraction to analyze document elements, such as macros. Document elements appear to be analyzed with both traditional countermeasures such as antivirus and Google’s customized security algorithms.
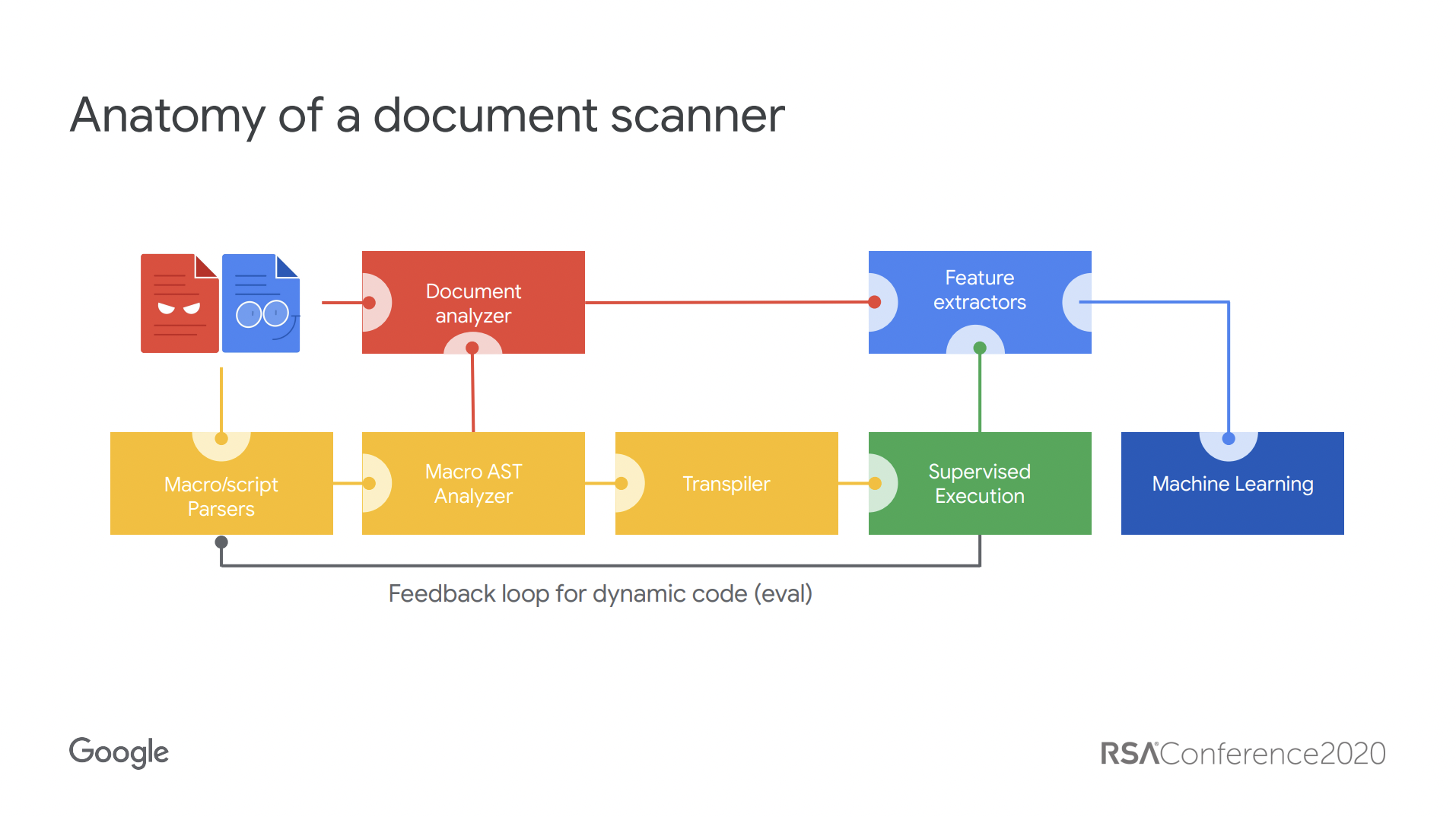
Document scanner workflow chat.
Source (PDF): Elie Bursztein
The third stage of the process involves compiling all of the attachment data and weighing them on a numerical scale. The software then issues a final accept or reject decision. If accepted, the attachment is included, and the email is sent.
Regarding business outcomes, Google claims that its solution detects malware approximately 99.9 percent of the time.